股票学.pdf(利用大模型预测股票的方法)
2023-11-07
浏览量:次
翻译整理自:arxiv 2306.11025.pdf
概述
本文提出了一项利用大语言模型(LLMs)出色的知识和推理能力进行可 解释金融时间序列预测的新研究。将机器学习模型应用于金融时间序 列带来了几个挑战,包括跨序列推理和推理的困难,从历史新闻、金 融知识图谱等纳入多模态信号的障碍,以及解释和解释模型结果的问 题。本文以纳斯达克-100股票为研究对象,利用公开可获取的历史股 价数据、公司元数据和历史经济/金融新闻。我们进行了实验,以说明 LLMs在为上述挑战提供统一解决方案方面的潜力。我们的实验包括尝 试使用GPT-4进行零射击/少射击推理,以及使用公共LLM模型Open LLaMA进行基于指令的微调。证明了所提出方法的性能优于一些基线, 包括广泛应用的经典ARMA-GARCH模型和梯度提升树模型。通过性 能比较结果和一些例子,我们发现LLM可以通过对文本新闻和价格时 间序列的信息进行推理并提取见解、利用交叉序列信息以及利用嵌入 LLM中的固有知识来做出深思熟虑的决策。此外,我们表明,公开可 用的LLM,如Open-LLaMA,经过微调后,可以理解指令,生成可解 释的预测并达到合理的性能,尽管与GPT-4相比相对较差。
方法
在本研究中,我们将重点放在NASDAQ-100股票价格时间序列 上,辅以有关股票公司的元数据和有关特定股票和更广泛的金 融/经济格局的相关金融新闻数据。我们主要关注的是预测每周/每月的股票收益(定义为股票价格从一周/月的开始到结 束的百分比变化),并附带解释。这个重点与大型语言模型(法学 硕士)的专业知识非常一致。 我们展示了法学硕士的结构化提示设计,并将最先进的GPT4模型[44]应用于零弹和少弹推理任务。为了进行微调,我们使 用公开可用的Open LLaMA[18]。我们还采用了思维链(Chain of Thoughts, COT)技术[38,64],在其他研究中发现该技术可以提高 法学硕士的有效性。
数据
1. 我们从Yahoo Finance使用yfinance包(pypi.org/project/yfinance/)下载每日NASDAQ-100股票价格数据。在本文中,我们首先将数字价格时间序列归一化为百分比变化时间序列,然后将百分比变化分类到不同的区间。例如,对于每周预测,我们将本周与上周之间的价格变化分为12个区间:“D5+”,“D5”,“D4”,“D3”,“D2”,“D1”,“U1”,“U2”,“U3”,“U4”,“U5”,“U5+”,其中“D5+”表示价格下降超过5%,“D i”(i=5,4,3,2,1)表示价格下降在(i-1)%到i%之间,“U5+”表示价格上涨超过5%,“U i”(i=1,2,3,4,5)表示价格上涨在(i-1)%到i%之间。不同粒度的推断可能会有不同数量的区间。例如,对于月度推断,我们允许i最大到10,并有相应的“D10+”和“U10+”类别。
2. 公司简介数据。我们使用GTP-4来生成公司描述,一般可能 影响公司股票价格的正面/负面因素。
3. 经新闻数据。我们使用谷歌自定义搜索API来获取每周 NASDAQ-100股票的前5名新闻故事。之后,我们使用GPT-4生 成摘要,并从每篇获得的新闻文章中提取关键字。
基于zero-shot和few-shot
在zero-shot和few-shot推理中,法学硕士展示了它们在没有任何 额外示例(zero-shot)或基于原始训练集之外的最小示例数(fewshot)的情况下生成响应的能力。在我们的零样本/少样本推理实验中,我们利用了基于指令 的提示。
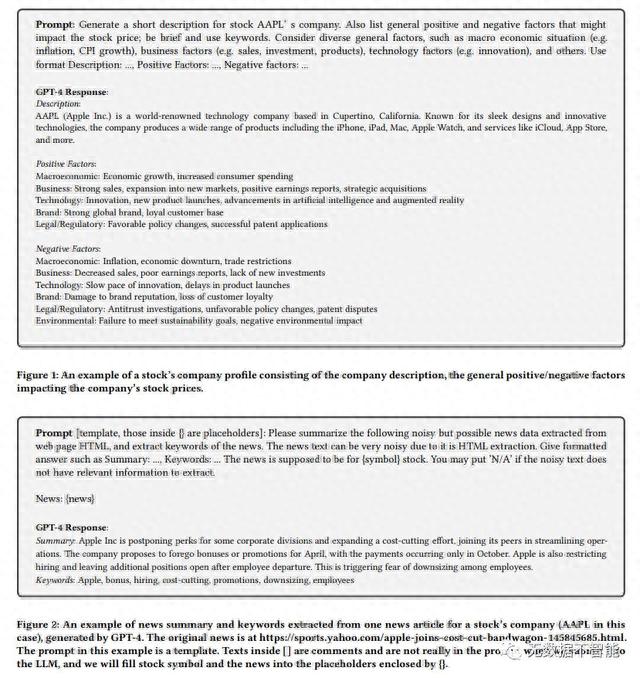

在图4中,包括指令、公司简介、历史时间新闻摘要/关键词序列与分类的股票价格时间序列混合在一起,以及跨序列的少样本学习示例。
为了避免提示文本中不必要的重复,我们有意提供与感兴趣主题相似的股票的少样本学习示例。这个设计也帮助我们证明了LLM可以考虑来自各种股票的跨序列信息。为了识别相似的股票,我们用一个问题来查询GPT-4,如“列出纳斯达克最相似的3只股票”。一个典型的回答,如“MSFT, GOOGL, AMZN”,展示了LLM对金融实体和概念之间关系的理解。通过聘请LLM,我们隐含地利用了其在金融实体和概念方面的广泛知识。
提示结构和指示已经根据经验进行了调整。例如,我们将指令分为两部分,将它们定位在提示的开头和结尾,这有助于模型更好地识别其任务:预测下周的摘要和关键词,而不是总结历史数据。预测的摘要和关键词作为相应的股票收益预测的解释。
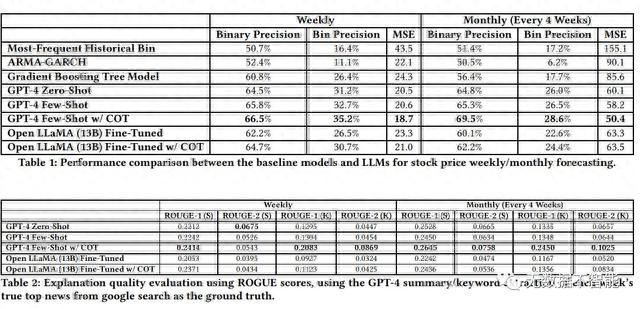
我们还尝试了思维链的方法[38,64,71],即“分步思考”的想法,通过在提示的最后附加“你能在最终确定输出之前一步一步推理吗?”令我们惊讶的是,这明显提高了几个点的性能(见第4.2节)。
图5说明了响应图4的逐步思考过程的结果,其中很明显,当生成明确的推理步骤时,GPT-4确定了以前被忽视的关于“收益报告”的关键点。
基于指令的微调与Open LLaMA
我们使用Open LLaMA 13B模型执行基于指令的微调,以查看与GPT-4相比,公开可用的模型的性能如何,特别是在微调之后。Open LLaMA 13B模型在其零射击推理中,通常倾向于复制提示的部分内容,而不是有效地执行提示中的指令。因此,如果不经历一个微调过程,它就无法正确地处理图4所示的基于指令的提示。因此,本文的重点是利用Open LLaMA模型进行微调。
基于指令的微调最近被证明在用特定指令指导模型的训练过程中是有效的[47,57]。我们创建了一个30K weekly forecasting plus的数据集7K月度预测,来源于从2017年6月到2022年6月的5年历史数据。不像GPT-4支持最多8K令牌大小,由于模型和硬件的限制,我们需要将提示压缩为1K令牌,以便对Open LLaMA进行微调。
对于每个微调示例,我们使用GPT-4将完整的历史元新闻摘要/关键字(例如,从第8周到最后一周,如图4所示)浓缩为单个,甚至更简洁的摘要/关键字对。同时,提示的“公司简介”和“预测示例”部分也分别浓缩为更简洁的摘要段落。
评估
结果显示了法学硕士在金融时间序列预测 中的有效性,其中“GPT-4 few-shot with COT”在预测精度和解 释质量方面始终表现最佳。研究结果还强调了思想链(chain -ofthought, COT)技术持续提高性能,以及利用公开可用的法学硕士 (如Open LLaMA)进行基于指令的微调的潜力,通过COT微调,与 GPT-4相比,可以实现合理的性能。
大模型核心论文三百篇带解读打包好啦!
左图是纯论文打包,右图包括解读文件
- 户外板块股票(体育产业板块11月7日涨258%,三夫户外领涨,主力资金净流入189亿元)
- 股票搞笑段子(幽默笑话:股市行情来了,段子手们也坐不住了)
- 公司收购 股票的影响(股份回购是否意味着市场见底?)
- 卖股票什么时间卖(炒股入门必备:交易时间和规则术语全解码,别再懵懂交易了)
- 什么股票 送股(上市公司2022年度分红方案一览)
- 300236上海新阳股票(上海新阳:公司持有的沪硅产业股份开展有转融通业务,未发生减持)
- 我国股票回购现状(深市公司密集披露回购增持进展 “真金白银”助力提振市场信心)
- 股票买卖统计表(推荐的全部股票统计表(一支暂无法计算收益率外,剩下的蒙对了))
- 伟明股票行情(去年抗跌的低估值业绩增长龙头股,今年市场表现却不佳,滞涨名单看这里)
- 15元左右股票(两市百元股排行榜)